Welcome to Part I of my series on ML-Agents in unity. In this article, I will give a brief overview of ML-Agents, and then talk about setting up a very simple learning environment and getting ML-Agents to successfully train a simple model.
Overview of ML-Agents
ML-Agents is a toolkit for unity provided by Unity Technologies for training reinforcement learning agents. Reinforcement learning is a machine learning process that trains a model by letting it loose in an environment and then giving it "rewards" when it behaves in the desired way.
ML-Agents' implementation of reinforcement learning involves building an "Agent" class. This class needs to contain code for:
- Making observations about the world and feeding them into the inputs of an AI "brain"
- Taking the outputs of the AI "brain" and using them to affect the world
- Giving rewards to the AI "brain" whenever desired outcomes occur
Once this is set up then the agent can be trained using a utility included in the ML-Agents package. As training proceeds, the agent will slowly learn how to behave in order to get the rewards. Once training is done the utility will save a model file, which describes the agent's behaviour at the end of the training. The model file can now be put back into Unity and the agent will behave in the desired way.
The Learning Environment
For this project I threw together a learning environment consisting of two teams with five soldiers each. Each soldier can be in one of five possible states:
- standing still
- moving forwards
- backing up
- turning left
- turning right
The soldiers carry a spear, that automatically damages enemies when it comes in contact with them. After each attack there is a short cool down before the spear can be used again. Both the damage dealt and the cool down are randomized within a small range of values.

After setting up the soldiers, a few additional things need to be added. The most important thing is a reset function that ensures everything will return to the same starting state. This is needed because to do a sufficient amount of training we must run and reset the world many times.
Basic Setup of the Agent
There are two basic functions that are part of the Agent class:
The first of them is the action function. The action function is responsible for taking the output of the AI Brain and affecting the world. In my case, I just want to select one of the possible soldier states I defined earlier, so a simple switch statement does the job:
:::C#
public override void AgentAction(float[] vectorAction) {
var selectedAction = Mathf.FloorToInt(vectorAction[0]);
switch(selectedAction) {
case 0:
MySoldier.CurrentAction = Soldier.SoldierAction.None;
break;
case 1:
MySoldier.CurrentAction = Soldier.SoldierAction.Forwards;
break;
case 2:
MySoldier.CurrentAction = Soldier.SoldierAction.Backwards;
break;
case 3:
MySoldier.CurrentAction = Soldier.SoldierAction.TurnLeft;
break;
case 4:
MySoldier.CurrentAction = Soldier.SoldierAction.TurnRight;
break;
default:
break;
}
}
In order for the brain to know it should output a number in the range 0-4 it
must be configured in unity. In the following screenshot the Branches
Size of 1 indicates I only want one output in my vectorAction array, and a
Branch 0 Size of 5 indicates i want numbers in the 0-4 range:
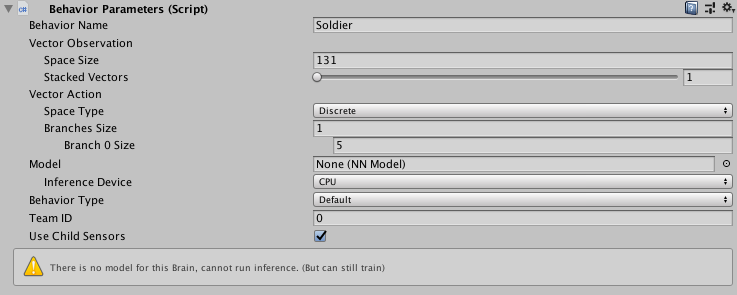
I also selected Discrete space type because I am interested in making a
selection (of states). Continuous space types are also very useful, but not
for my particular case. Choosing the AgentAction has some bearing with designing
an agent that will train nicely, but often it's highly constrained by the
problem.
The second important basic setup function is the Heuristic. This one is strictly optional, but in my earlier escapades with ML-Agents I chose not to implement it and paid the price. The heuristic simply allows you to write some conventional logic and have it pass-through the AgentAction function to affect the world. This is very useful for testing your code in a controlled way. In this instance I setup my heuristic to map keyboard inputs to the five states and immediately discovered I had inverted my left and right turning directions. Once training is begun the agent's behaviour is very chaotic, spotting such a thing would be nearly impossible!
Implementing the heuristic can be done in many ways. The aforementioned mapping to keyboard inputs is a common and useful pattern. In my case I also implemented a "do-nothing" path in the heuristic which was selected by an enum, this allowed me to move one agent with the keyboard while the others stayed still. Another useful pattern when possible is to implement a very simple scripted AI, this isn't always possible but when it is it can give you confidence in your training environment.
Observations and Rewards
The first big decision you will need to make for your agent is how it will perceive the world, this all goes into the CollectObservation function. As for the design of this function, there are a great many things you can collect as observation, in my case I collected a bit of the soldier's state and some ray-traces of the world around them. The soldier's state includes
- The soldier's X Position in the world
- The soldier's Z Position in the world
- The soldier's rotation
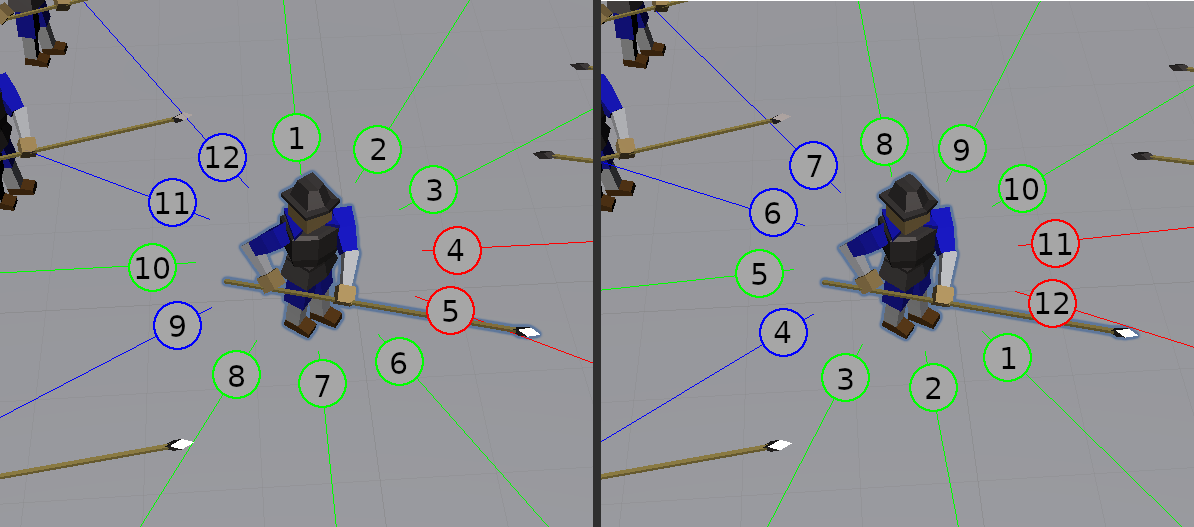
And for each of the (equally spaced) traces around the soldier I collected
- The distance of the ray-trace
- If it hit a soldier (1.0 if it did, or else 0.0)
- If it hit an enemy soldier (1.0 if it did, or else 0.0)
- The rotation of any soldier it hit (Or else 0.0)
When I initially set this up I chose to have 32 evenly spaced traces around the soldier, adding this all up (3 state values plus 32 * 4 ray-trace values) I got a total of 131 observations, and so had to set the input accordingly:
The other big decision to make at this point is how to reward the agent. I chose to give a reward of 1.0 to each agent on the winning side, and a reward of 0.1 each time an agent deals damage. This is a very simple reward structure, but generally rewards should be as few as needed to guide the agent to completing it's task.
Hyperparameters and Training
With all that done there is only one more thing to do before training, and that's setting the agent hyperparameters. In this article I'm using the term hyperparameters to refer only to those defined in the ML-Agents YAML config file. Technically many of the things you write in code are also considered hyperparameters, such as your rewards and how you collect observations.
For my case it was fine to skip configuring hyperparameters and just use the defaults. Setting up hyperparameters is a tricky thing that requires patience and experience (which I do not have!). I may cover it in more detail in a future article. For now though, the defaults served me fine.
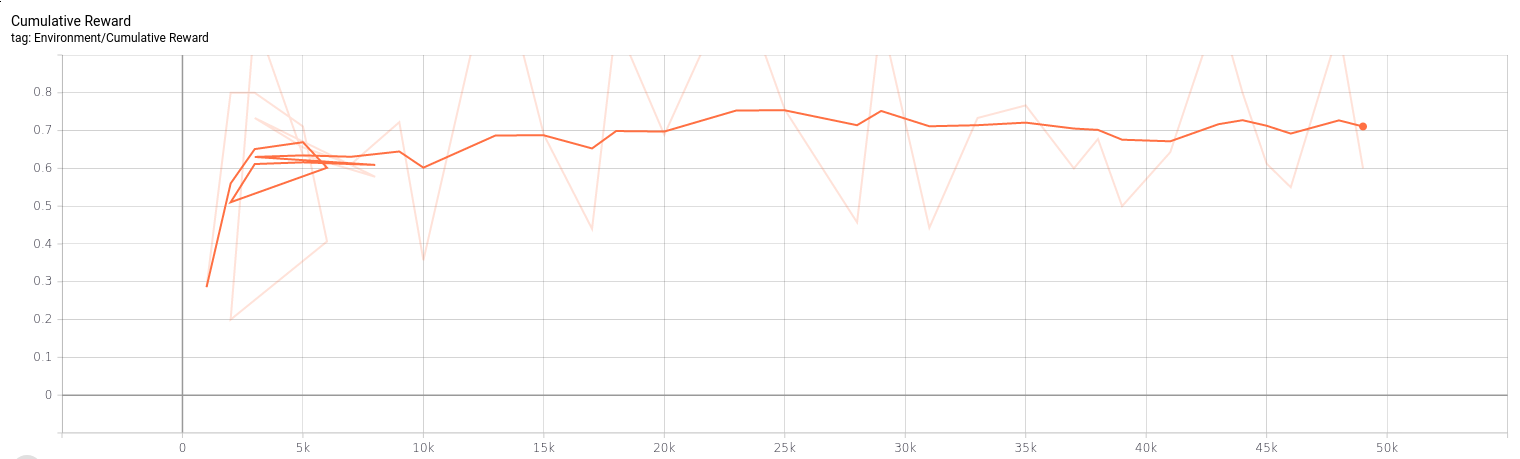
Initial training however, did not serve me fine. There's a tool (which ships with ML-Agents) called tensorboard, and it's what produced this nice graph of the agent not learning much at all over 15 minutes of training. While 15 minutes is not a very long time to train, I expected to see at least some positive movement. Since nothing seemed to be happening I canceled training here to make some adjustments.
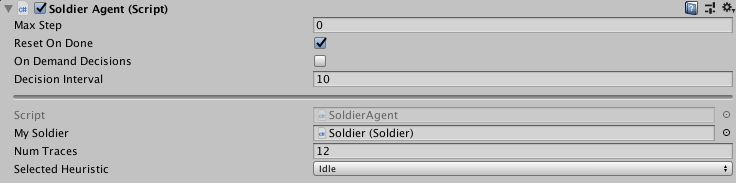
So I went back and made some adjustments to help out. First I increased the
frequency the agent makes decisions (Decision Interval) from once a frame to
once per ten frames. Besides having a noticeable performance benefit (and
thereby allowing me to train at higher time acceleration) this also makes the
problem easier to be trained train by reducing the number of decisions needed in
one "battle" and mostly eliminating suboptimal decisions (If we start doing one
thing, immediately changing our mind the next frame is probably not
super-useful)
The next change I made was reducing the number of traces from 32 to 12. Again this gave a bit of a performance increase, and it also simplified the neural networks within the agent. One other important thing it did: remember how I said the default hyperparameters were fine? I lied! Before there were more input nodes than there were nodes on the hidden layers of the neural network, this is generally a bad thing and should be avoided. After reducing the number of inputs now the default hyperparameters were fine!
Finally, I tweaked the rewards a little bit, at this stage I was not so much interested in the soldiers developing tactics to win the battle (though that's definitely very cool and is my longer term goal) but I just wanted them to get in there and duke it out. To this end I increased the "Dealing Damage" reward to 1.0 and removed the victory reward entirely.
Revision and Results
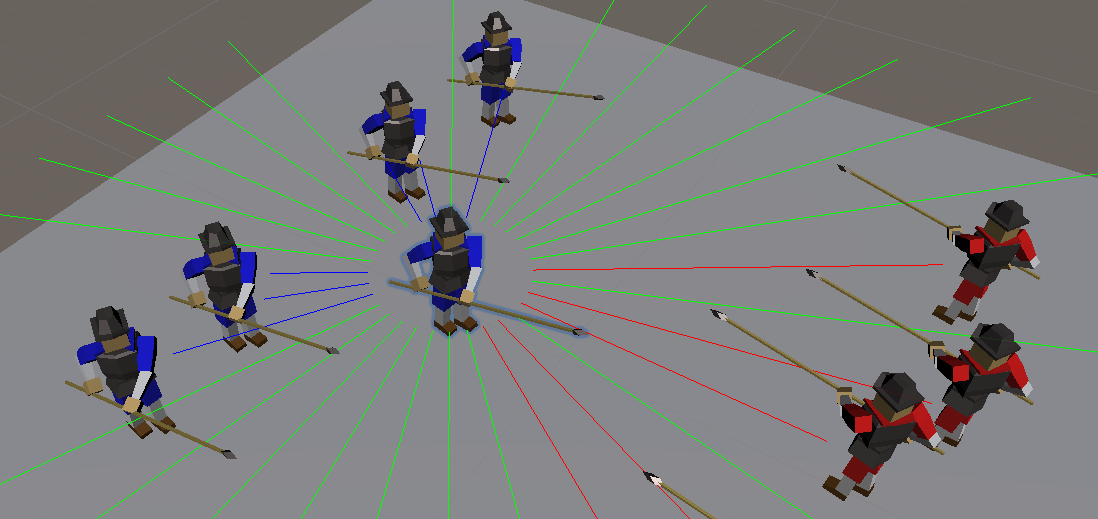
So I trained that agent for 500,000 steps which took 3.5 hours on my machine. This time the agent actually learned... well whatever this is:
As you can see, the red team "kind of" knows how to advance, and then they have an idea of flailing around hoping to kill something. The blue team is hopeless, they just turn their back on the enemy and refuse to fight (Pacifists!). Considering this took 3.5 hours things don't look very successful so far, but this can be done better.
Up until this point I had been making the traces around my agent starting from
the global +Z direction and then going around clockwise. Instead I wanted to
change this so the traces start at the agent's local +Z and rotate as the
agent rotates. This way, an input that points to the agent's right will always
point to it's right no matter which way it turns.
So I trained again, I let it run an hour and a half but after 15 minutes training had plateaued.
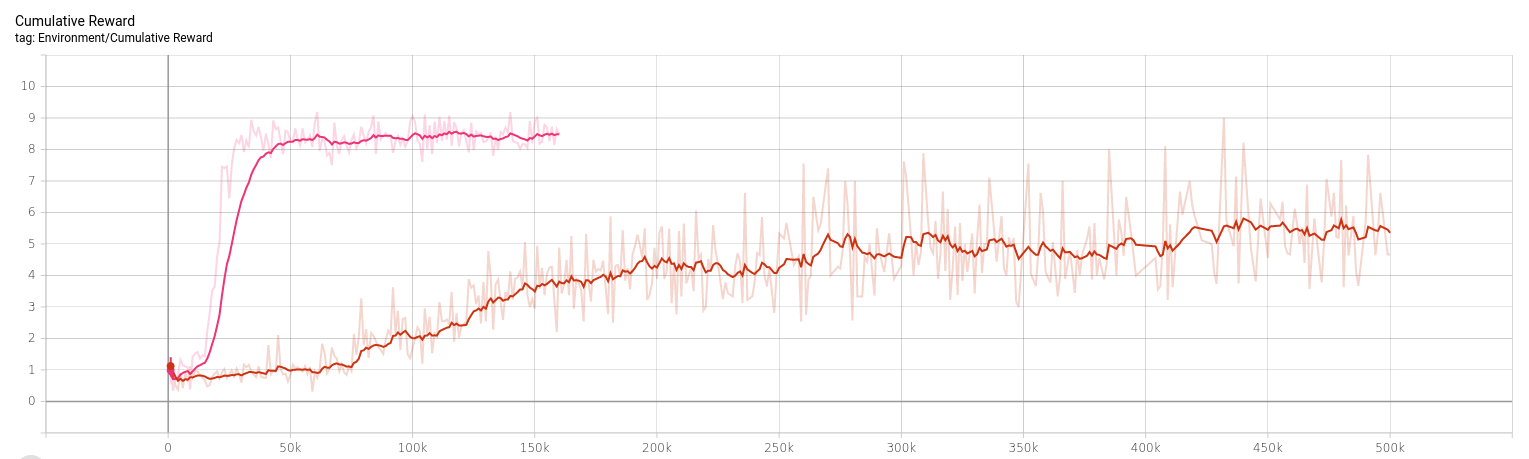
That's pretty great! In just 15 minutes it already learned to get more rewards on average than the old method did in 3.5 hours. It was plateauing; which means either it's successfully trained or it got stuck. There's only one way to find out which one, and that's to watch it in action:
Pretty cool! I made a few adjustments after this, but this article is already getting a bit long so I'll leave those for another time. If you have any questions please leave a comment, you can also find me @zchfvy on twitter!